Lesson 4
The Mean
4.1: Which One Doesn’t Belong: Division
Which expression does not belong? Be prepared to explain your reasoning.
\(\displaystyle \frac {8+8+4+4}{4}\)
\(\displaystyle \frac {10+10+4}{4}\)
\(\displaystyle \frac {9+9+5+5}{4}\)
\(\displaystyle \frac {6+6+6+6+6}{5}\)
4.2: Spread Out and Share
- The kittens in a room at an animal shelter are arranged in five crates, as shown.

-
The manager of the shelter wants the kittens distributed equally among the crates. How might that be done? How many kittens will end up in each crate?
-
The number of kittens in each crate after they are equally distributed is called the mean number of kittens per crate, or the average number of kittens per crate.
Explain how the expression \(10 \div 5\) is related to the average.
-
Another room in the shelter has 6 crates. No two crates contain the same number of kittens, and there is an average of 3 kittens per crate.
Draw or describe at least two different arrangements of kittens that match this description. You may choose to use the applet to help.
-
- Five servers were scheduled to work the number of hours shown. They decided to share the workload, so each one would work equal hours.
- Server A: 3
- Server B: 6
- Server C: 11
- Server D: 7
- Server E: 4
- On the grid on the left, draw 5 bars whose heights represent the hours worked by servers A, B, C, D, and E.
- Think about how you would rearrange the hours so that each server gets a fair share. Then, on the grid on the right, draw a new graph to represent the rearranged hours. Be prepared to explain your reasoning.
- Based on your second drawing, what is the average or mean number of hours that the servers will work?
- Explain why we can also find the mean by finding the value of \(31 \div 5\).
- Which server will see the biggest change to work hours? Which server will see the least change?
Server F, working 7 hours, offers to join the group of five servers, sharing their workload. If server F joins, will the mean number of hours worked increase or decrease? Explain how you know.
4.3: Travel Times (Part 2)
-
Here are dot plots showing how long Diego’s trips to school took in minutes—which you studied earlier—and how long Andre’s trips to school took in minutes. The dot plots include the means for each data set, marked by triangles.

- Which of the two data sets has a larger mean? In this context, what does a larger mean tell us?
- Which of the two data sets has larger sums of distances to the left and right of the mean? What do these sums tell us about the variation in Diego’s and Andre’s travel times?
-
Here is a dot plot showing lengths of Lin’s trips to school.
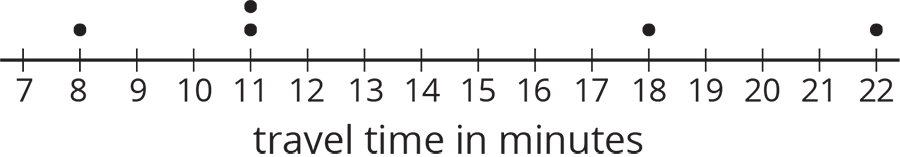
- Calculate the mean of Lin’s travel times.
- Complete the table with the distance between each point and the mean as well whether the point is to the left or right of the mean.
time in minutes distance from the mean left or right of the mean? 22 18 11 8 11 - Find the sum of distances to the left of the mean and the sum of distances to the right of the mean.
- Use your work to compare Lin’s travel times to Andre’s. What can you say about their average travel times? What about the variability in their travel times?
Summary
Sometimes a general description of a distribution does not give enough information, and a more precise way to talk about center or spread would be more useful. The mean, or average, is a number we can use to summarize a distribution.
We can think about the mean in terms of “fair share” or “leveling out.” That is, a mean can be thought of as a number that each member of a group would have if all the data values were combined and distributed equally among the members.
For example, suppose there are 5 bottles which have the following amounts of water: 1 liter, 4 liters, 2 liters, 3 liters, and 0 liters.

To find the mean, first we add up all of the values. We can think of as putting all of the water together: \(1+4+2+3+0=10\).

To find the “fair share,” we divide the 10 liters equally into the 5 containers: \(10\div 5 = 2\).

Suppose the quiz scores of a student are 70, 90, 86, and 94. We can find the mean (or average) score by finding the sum of the scores \((70+90+86+94=340)\) and dividing the sum by four \((340 \div 4 = 85)\). We can then say that the student scored, on average, 85 points on the quizzes.
In general, to find the mean of a data set with \(n\) values, we add all of the values and divide the sum by \(n\).
The mean is often used as a measure of center of a distribution. This is because the mean of a distribution can be seen as the “balance point” for the distribution.
The sum of the distances for the data points to the left of the mean is equal to the sum of the distances for the data points to the right of the mean. So, the mean is often near the middle of the distribution, especially when the data is symmetric.
Glossary Entries
- average
The average is another name for the mean of a data set.
For the data set 3, 5, 6, 8, 11, 12, the average is 7.5.
\(3+5+6+8+11+12=45\)
\(45 \div 6 = 7.5\)
- mean
The mean is one way to measure the center of a data set. We can think of it as a balance point. For example, for the data set 7, 9, 12, 13, 14, the mean is 11.

To find the mean, add up all the numbers in the data set. Then, divide by how many numbers there are. \(7+9+12+13+14=55\) and \(55 \div 5 = 11\).
- measure of center
A measure of center is a value that seems typical for a data distribution.
Mean and median are both measures of center.